OCR在資產管理系統的應用
OCR是通過算法識別出圖像中的文字內容,算是圖像識別的一個分支。那為什么固定資產管理系統中會用到 OCR 呢?
一、從業務說起:為什么需要 OCR?
為什么固定資產管理系統中會用到 OCR 呢?就得從梳理需求時遇到的問題說起。
固定資產的全生命周期管理的第一步是“資產入庫”,而入庫是一個非常繁瑣的過程,需要將大量信息錄入系統。通過前期調研發現錄入過程費時費力,還經常出現錄入錯誤的問題(比如設備型號、序列碼是較長的數字、字母序列,人工錄入很容易出錯)。
有沒有辦法解決這個痛點呢?受證件識別的啟發,我們想到了 OCR 輔助人工錄入,那么接下來就是調研這種方案的可行性了。
二、關于 OCR
OCR,也就是 optical character recognation(光學字符識別),是通過算法識別出圖像中的文字內容,算是圖像識別的一個分支。OCR 對純文本的識別已經比較成熟,識別率普遍可以達到 90%以上,百度、阿里、騰訊等各大廠都有相應的服務可以直接調用。
1. OCR 分類
OCR 技術可以按字體類別、識別語言、識別場景進行細分,每個細分的算法有所不同,現在暫時還沒有非常通用的算法同時適用于多個分類。
其中:
- 印刷體識別成熟度要高于手寫體(原因也比較好理解,印刷體比較規范,手寫體五花八門有時候人都難以辨認)。
- 中文和西文的識別成熟度高于小語種,中英文混合識別也能比較好的解決。
- 自然環境中的文字識別難度也要大于文檔圖片識別,因為自然環境中文字所處環境要更加復雜,文字檢測難度要大于文檔圖片。
- 對特定格式文檔(如身份證、發票、成績單)的識別要好于自由文檔(文字、表格、圖片、公式混排)。
調研到這里,我們可以發現:OCR 輔助資產入庫的需求,屬于上述分類里的【自然環境】下的【中英文混合】【印刷體】識別。目前文字識別印刷體識別已經比較成熟,但自然環境下的拍照可能會給識別帶來一些難度,初步判斷 OCR 輔助人工進行資產入庫信息錄入是可行的。
2. OCR 算法理解
既然 OCR 是圖像識別的一種,那么處理的流程就和大多數圖像識別算法是一致的,即預處理-圖像檢測-圖像識別。以自然環境下的文字識別為例,OCR 算法的工作流程大概是這樣的:
預處理:文本經過掃描或拍照后會發生形變等問題,會對識別造成干擾,預處理就是通過灰度化、二值化,傾斜校正等方式消除這種干擾,以提高識別準確率。其中傾斜矯正的常見算法有投影法、hough 法等。
文字檢測:目的在于找出文字的區域,是文字識別的基礎。簡單背景(e.g.掃描、截屏)和復雜背景(e.g.廣告牌、說明書)下的文字檢測方法差異較大,實現算法可以分為傳統 CV 算法和 DL 算法兩大類。
- 形態學方法:通過膨脹腐蝕等操作找到文字區域,只適用于簡單背景。
- MSER:常用的傳統文字檢測算法,檢測速度快,在簡單背景和部分復雜背景中適用。但背景特別復雜時,檢測效果可能較差。
- CTPN:是 CNN 和 RNN 相結合的算法,適用于簡單和復雜背景的文字檢測,但文字傾斜時的檢測效果較差。
- SegLink:可以用于檢測傾斜文字(但文字間隔不能太大)。
- EAST:端到端文本檢測方法,也可用于檢測傾斜文字,檢測的準確性和速度都不錯。
文字識別:文字識別又根據文字的長度分為定長(e.g.驗證碼)和不定長。不定長文字識別現在主要是通過 DL 算法實現,目前兩大主流技術是 CRNN OCR 和 attention OCR。由于文字識別的特殊性,雖然其表現形式是圖像,但本質是序列化的文本。所以不論是CRNN還是attention,思路其實都是用CNN提取特征,然后用RNN處理序列化,充分運用了文本圖像的所有信息。
通過對 OCR 工作流程以及主流算法的了解,我們能對后續技術實現有個大概的認識,和 RD battle 時候也更加有底了。
三、功能設計
1. 核心場景
最近公司采購了一批新的辦公電腦,資產管理部門的小方來到倉庫打算對這批電腦進行入庫登記,他拿出手機打開 app,對著每臺電腦上的標簽進行拍照,標簽上的信息就被識別出來填入相應的輸入框,很快小方就完成了入庫登記的工作。
2. 業務流程
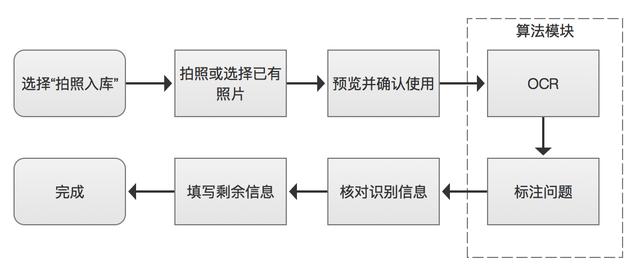
對用戶來說 OCR 識別的過程是無感的,操作上只是用拍照代替了手工填寫某些字段的步驟。
3. OCR 實現中的幾點考慮
1)輸入和輸出
在本需求中,OCR 算法的輸入就是用戶拍攝的照片,然后需要把算法的識別結果填寫到資產登記表單中相應的輸入框中,所以需要確定 :a)識別哪些字段;b)每個字段識別出的結果。
a)識別哪些字段:綜合考慮了常見的資產標簽類型,結合最開始我們遇到的問題“字母數字序列輸入容易出錯且效率低”,確定了【資產名稱】【型號】【SN碼】三個需要識別的字段,也就是 OCR 處理完的結果只是中間結果,后邊還需要做一個類似標注問題的處理(標注問題的處理方法暫不在這里展開)。
b)文字識別的結果反映到頁面上就是把識別出來的字段填到相應的文本框中,所以需要算法部分輸出的結果是“型號:Lenovo IdeaPad Y580”這樣的 k-v 形式。
2)服務端 or 客戶端
模型直接放在客戶端的好處是可以離線使用,缺點也十分明顯:一是識別準確率會受影響;二是安裝包會變大;三是算法迭代必須等軟件整體更新。所以除非是特殊的離線要求,還是把識別放在服務端好一點。
3)技術選型
實現途徑無非兩種:自研或者調用第三方服務。
自研的話,也不太可能從輪子造起,一般是在成熟的開源項目(如 chinese-ocr)或者是團隊已有的算法基礎上優化,最后得到的模型在特定場景的準確度肯定會比通用服務好。
自研算法主要包括兩方面的工作:一是數據集獲取、標注;二是模型優化,時間和人力成本都較高。但出于團隊發展、算法積累以及后續可能需要私有化部署的考慮,我們最后還是選擇了自研的形式。
為了給自研提供支撐和幫助,我對第三方服務也做了一些調研,如果有小伙伴恰好有類似的需求也可以參考。百度、阿里、騰訊三個開發平臺都沒有針對我們這種需求的特定解決方案,所以只能使用通用 OCR 模型。
可見通用 OCR 模型已經能比較好的識別出資產標簽信息,所以調用第三方服務的方案也是可行的。
4)性能需求
- 由于用戶需要即時獲得識別結果,正常網絡環境下,處理單張圖片請求到返回結果應該在2s以內;
- 由于后續流程中有人工確認、更正信息的步驟,所以在平衡精度和召回率時,可以適當地提高召回率。
4. 優化思路:批量處理
個人認為批量操作是 2B 業務的一個核心思想。設備特別多的情況下每個設備拍照-錄入這種流程也會比較慢,而且一批設備很大概率上是同一品牌型號的,所以批量錄入的需求是存在且可以實現的(比如輸入相同信息,然后批量識別 SN 碼)。
實現批量錄入的需求,一方面前端業務流程需要調整,另一方面 OCR 算法為適應批量識別在速度上也需要提升。這也是這個功能點后續優化的方向~